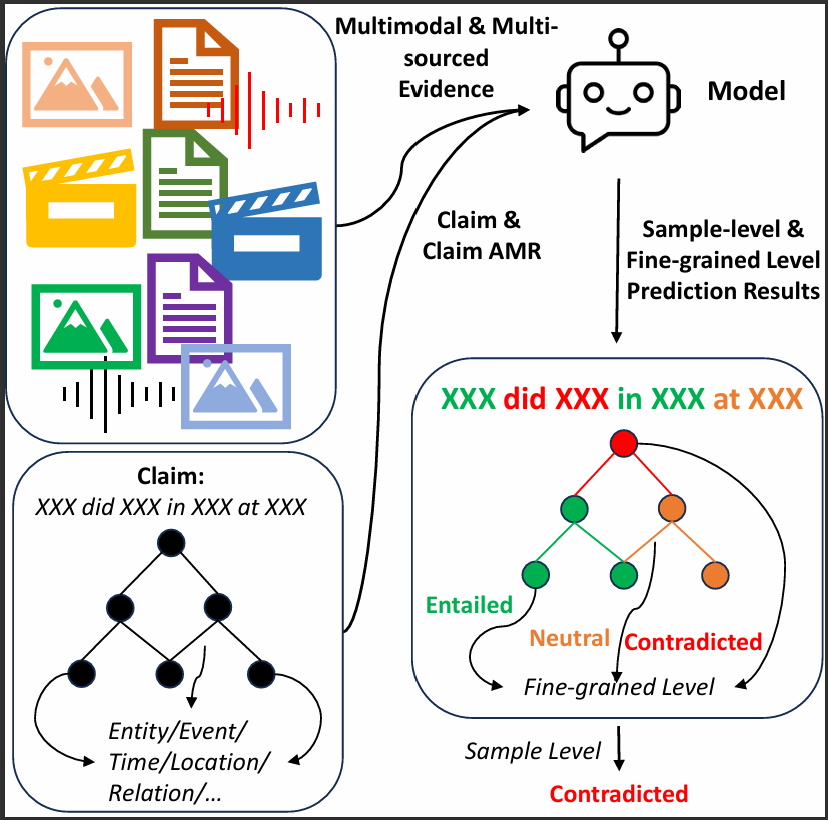
Fact-checking claims is a highly laborious task that involves understanding how each factual assertion within the claim relates to a set of trusted source materials. Existing approaches make sample-level predictions but fail to identify the specific aspects of the claim that are troublesome and the specific evidence relied upon. In this paper, we introduce a method and new benchmark for this challenging task. Our method predicts the fine-grained logical relationship of each aspect of the claim from a set of multimodal documents, which include text, image(s), video(s), and audio(s). We also introduce a new benchmark (M3DC) of claims requiring multimodal multidocument reasoning, which we construct using a novel claim synthesis technique. Experiments show that our approach outperforms other models on this challenging task on two benchmarks while providing finer-grained predictions, explanations, and evidence.
ACL
MetaSumPerceiver: Multimodal Multi-Document Evidence Summarization for Fact-Checking
Ting-Chih Chen, Chia-Wei Tang and Chris Thomas
In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL).
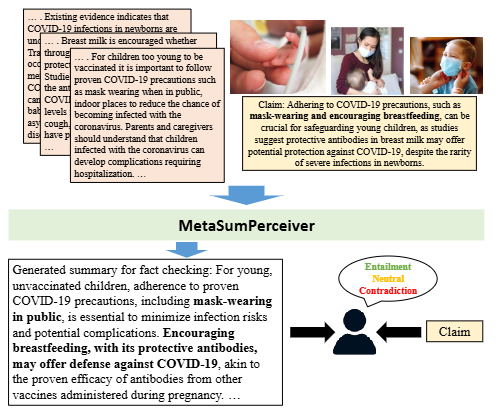
Fact-checking real-world claims often requires reviewing multiple multimodal documents in order to assess the claim’s truthfulness, a highly laborious and time-consuming task. In this paper, we present a summarization model crafted to generate claim-specific summaries useful for fact-checking from multimodal multi-document datasets. The model takes inputs in the form of documents, images, and a claim, with the objective of assisting in fact-checking tasks. We introduce a dynamic perceiver-based model that is able to handle inputs from multiple modalities of arbitrary lengths. To train our model, we leverage a novel reinforcement learning-based entailment objective in order to generate summaries that provide evidence distinguishing between different truthfulness labels. To assess the efficacy of our approach, we conduct experiments on both an existing benchmark as well as a new dataset of multi-document claims which we contribute. Our approach outperforms the SOTA approach by 4.6% in the claim verification task on the MOCHEG dataset and demonstrates strong performance on our new Multi-News-Fact-Checking dataset.
2023
MS thesis
Multimodal Multi-Document Evidence Summarization For Fact-Checking
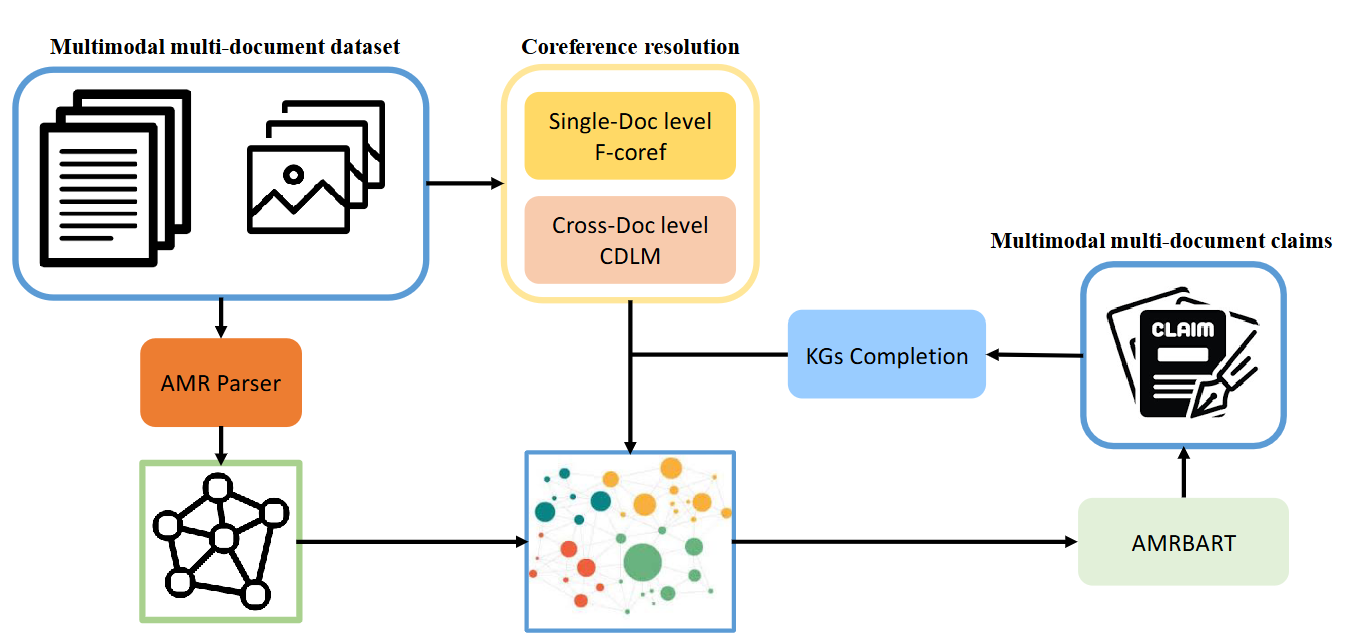
Fact-checking real-world claims is a time-consuming task that involves reviewing various documents to determine the truthfulness of claims. The current research challenge is the absence of a method to supply evidence that can assist human fact-checkers effectively. To solve the research challenge, we propose the MetaSumPerceiver model designed to create claim-specific summaries for fact-checking. The MetaSumPerceiver model, a dynamic perceiver-based model, takes inputs in the form of documents, images, and a claim, with the objective of assisting in fact-checking tasks and handling inputs of varying lengths from multiple modalities. To train this model, we use a novel reinforcement learning-based entailment objective to generate summaries that offer evidence distinguishing between different truthfulness labels. To assess our model's effectiveness, we introduce the KG2Claim approach to generate multimodal multi-document claims. This approach integrates information from multimodal multi-document sources into the knowledge graphs. Our main objective is to examine whether the multimodal multi-document claims align with the information in articles. The findings from MetaSumPerceiver show that more than 70% of our claims are entailment claims. This validates that KG2Claim effectively generates claims that entail the information from multimodal multi-document sources. Subsequently, we conduct evidence summarization experiments on an existing benchmark and a new dataset of multi-document claims that we contributed. Our approach surpasses the state-of-the-art method by 4.2% in the claim verification task on the MOCHEG dataset and demonstrates strong performance on our Multi-News-Fact-Checking dataset.
2020
IAM
Application of LSTM Neural Network in Stock Price Movement Forecasting with Technical Analysis Index
Ting-Chih Chen and Chin-I Lee
In Proceedings of the 17th International Conference on Innovation and Management (IAM).
There are many factors will be driving stock prices, such as earnings, economy, expectations, and emotion. Stock prices are volatile because these factors daily change frequently; it is a big challenge to accurately predict the future stock prices. Recently, there are lots of studies in the area of applying Machine Learning for analyzing price patterns and predicting stock prices, they would get satisfactory results in making instantaneous investment decisions. In this paper, we discuss the Long Short-Term Memory (LSTM) algorithms applied for stock trading to predict the rise and fall of stock prices before the actual event of an increase or decrease value in the stock market occurs. Aiming to raise up the rate prediction accuracy, we achieve to build a prediction model, execute a series of experiments, and then provide the index reference to buy a stock before the price rises, or sell it before its value declines.